Hadoop的歷史 數(shù)字技術(shù)的演進(jìn)服務(wù)
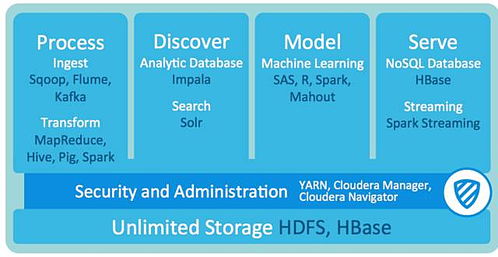
Hadoop是當(dāng)今大數(shù)據(jù)處理領(lǐng)域的基石技術(shù)之一,其發(fā)展歷程深刻反映了數(shù)字技術(shù)服務(wù)的演進(jìn)。Hadoop的起源可追溯到2002年,當(dāng)時(shí)Apache Nutch項(xiàng)目面臨網(wǎng)頁(yè)索引數(shù)據(jù)量激增的挑戰(zhàn)。受Google在2003年和2004年發(fā)布的MapReduce和Google File System(GFS)論文啟發(fā),Doug Cutting和Mike Cafarella開(kāi)始開(kāi)發(fā)一個(gè)分布式計(jì)算框架,并以其兒子玩具大象的名字命名為'Hadoop'。
2006年,Hadoop正式成為Apache軟件基金會(huì)的頂級(jí)項(xiàng)目,標(biāo)志著其開(kāi)源生態(tài)的建立。隨著數(shù)字經(jīng)濟(jì)的興起,Hadoop迅速被Yahoo、Facebook等科技巨頭采用,用于處理海量用戶(hù)數(shù)據(jù),提供高效的搜索、廣告推薦等數(shù)字服務(wù)。其核心組件HDFS(分布式文件系統(tǒng))和MapReduce(并行處理模型)解決了傳統(tǒng)數(shù)據(jù)庫(kù)無(wú)法應(yīng)對(duì)的PB級(jí)數(shù)據(jù)存儲(chǔ)與計(jì)算問(wèn)題。
2010年后,Hadoop生態(tài)系統(tǒng)不斷擴(kuò)展,涌現(xiàn)出HBase、Hive、Pig等工具,進(jìn)一步推動(dòng)了云計(jì)算、物聯(lián)網(wǎng)和人工智能等數(shù)字技術(shù)服務(wù)的發(fā)展。例如,企業(yè)利用Hadoop分析用戶(hù)行為數(shù)據(jù),優(yōu)化個(gè)性化服務(wù);政府機(jī)構(gòu)借助其處理公共數(shù)據(jù),提升智慧城市管理效率。
盡管近年來(lái)新興技術(shù)如Spark和云原生方案部分替代了Hadoop的角色,但Hadoop的歷史貢獻(xiàn)不可磨滅。它不僅是開(kāi)源文化的典范,更奠定了現(xiàn)代數(shù)據(jù)驅(qū)動(dòng)型數(shù)字服務(wù)的基礎(chǔ),從電子商務(wù)到醫(yī)療健康,無(wú)處不在的數(shù)字化應(yīng)用都受益于其分布式架構(gòu)思想。未來(lái),Hadoop的遺產(chǎn)將繼續(xù)影響下一代大數(shù)據(jù)技術(shù)的創(chuàng)新,助力全球數(shù)字經(jīng)濟(jì)的持續(xù)變革。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://m.imeasy.cn/product/22.html
更新時(shí)間:2026-05-23 22:43:41